Original: Simon Willison · 09/02/2026
Summary
Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured datKey Insights
“Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured data.” — Introduction to the research focus on SQL generation for agent operations.
“The biggest impact was the models themselves - with frontier models beating the leading open source models.” — Highlighting the significant performance difference between frontier and open source models.
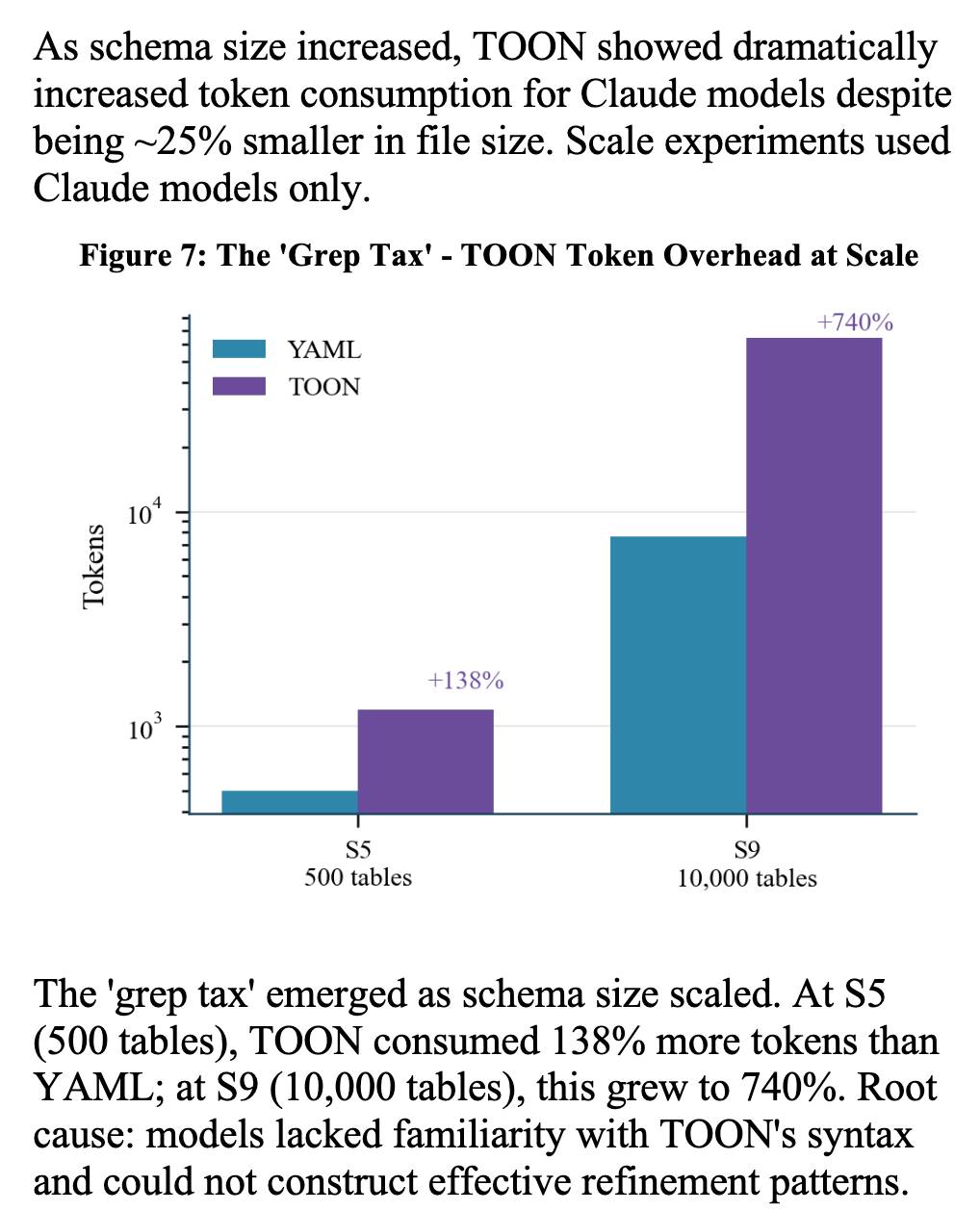
“The ‘grep tax’ emerged as schema size scaled.” — Discussing the increased token consumption by models when using TOON format at larger scales.
Topics
Full Article
Published: 2026-02-09
Source: https://simonwillison.net/2026/Feb/9/structured-context-engineering-for-file-native-agentic-systems/#atom-everything
Structured Context Engineering for File-Native Agentic Systems New paper by Damon McMillan exploring challenging LLM context tasks involving large SQL schemas (up to 10,000 tables) across different models and file formats:
Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured data, comprising 9,649 experiments across 11 models, 4 formats (YAML, Markdown, JSON, Token-Oriented Object Notation [TOON]), and schemas ranging from 10 to 10,000 tables.Unsurprisingly, the biggest impact was the models themselves - with frontier models (Opus 4.5, GPT-5.2, Gemini 2.5 Pro) beating the leading open source models (DeepSeek V3.2, Kimi K2, Llama 4). Those frontier models benefited from filesystem based context retrieval, but the open source models had much less convincing results with those, which reinforces my feeling that the filesystem coding agent loops aren’t handled as well by open weight models just yet. The Terminal Bench 2.0 leaderboard is still dominated by Anthropic, OpenAI and Gemini. The “grep tax” result against TOON was an interesting detail. TOON is meant to represent structured data in as few tokens as possible, but it turns out the model’s unfamiliarity with that format led to them spending significantly more tokens over multiple iterations trying to figure it out:
 Via @omarsar0
Via @omarsar0
Key Takeaways
Notable Quotes
Using SQL generation as a proxy for programmatic agent operations, we present a systematic study of context engineering for structured data.Context: Introduction to the research focus on SQL generation for agent operations.
The biggest impact was the models themselves - with frontier models beating the leading open source models.Context: Highlighting the significant performance difference between frontier and open source models.
The ‘grep tax’ emerged as schema size scaled.Context: Discussing the increased token consumption by models when using TOON format at larger scales.
Related Topics
- [[topics/agent-native-architecture]]
- [[topics/ai-agents]]
- [[topics/prompt-engineering]]
Related Articles
[AINews] Claude Sonnet 4.6: clean upgrade of 4.5, mostly better with some caveats
Swyx · explanation · 70% similar
I dream about AI subagents; they whisper to me while I'm asleep
Geoffrey Huntley · explanation · 69% similar
Effective context engineering for AI agents
Anthropic Engineering · explanation · 69% similar