Documentation Index
Fetch the complete documentation index at: https://plantis.ai/llms.txt
Use this file to discover all available pages before exploring further.
Original: Simon Willison · 19/02/2026
Summary
SWE-bench is one of the benchmarks that the labs love to list in their model releases. SWE-bench is one of the benchmarks that the labs love to list in their model releases. The official leaderboard is infrequently updated but they just did a full run of it against the current generation of models, which is notable because it’s always good to see benchmark results like this that *wereKey Insights
“SWE-bench is one of the benchmarks that the labs love to list in their model releases.” — Highlighting the importance of SWE-bench in evaluating AI models.
“It’s interesting to see Claude Opus 4.5 beat Opus 4.6, though only by about a percentage point.” — Discussing the surprising performance of older AI model versions over newer ones.
“I’m impressed at how well this worked - Claude injected custom JavaScript into the page to draw additional labels on top of the existing chart.” — Expressing satisfaction with Claude’s ability to manipulate web content for enhanced visualization.
Topics
Full Article
Published: 2026-02-19
Source: https://simonwillison.net/2026/Feb/19/swe-bench/#atom-everything
SWE-bench February 2026 leaderboard update SWE-bench is one of the benchmarks that the labs love to list in their model releases. The official leaderboard is infrequently updated but they just did a full run of it against the current generation of models, which is notable because it’s always good to see benchmark results like this that weren’t self-reported by the labs. The fresh results are for their “Bash Only” benchmark, which runs their mini-swe-bench agent (~9,000 lines of Python, here are the prompts they use) against the SWE-bench dataset of coding problems - 2,294 real-world examples pulled from 12 open source repos: django/django (850), sympy/sympy (386), scikit-learn/scikit-learn (229), sphinx-doc/sphinx (187), matplotlib/matplotlib (184), pytest-dev/pytest (119), pydata/xarray (110), astropy/astropy (95), pylint-dev/pylint (57), psf/requests (44), mwaskom/seaborn (22), pallets/flask (11). Correction: The Bash only benchmark runs against SWE-bench Verified, not original SWE-bench. Verified is a manually curated subset of 500 samples described here, funded by OpenAI. Here’s SWE-bench Verified on Hugging Face - since it’s just 2.1MB of Parquet it’s easy to browse using Datasette Lite, which cuts those numbers down to django/django (231), sympy/sympy (75), sphinx-doc/sphinx (44), matplotlib/matplotlib (34), scikit-learn/scikit-learn (32), astropy/astropy (22), pydata/xarray (22), pytest-dev/pytest (19), pylint-dev/pylint (10), psf/requests (8), mwaskom/seaborn (2), pallets/flask (1). Here’s how the top ten models performed:
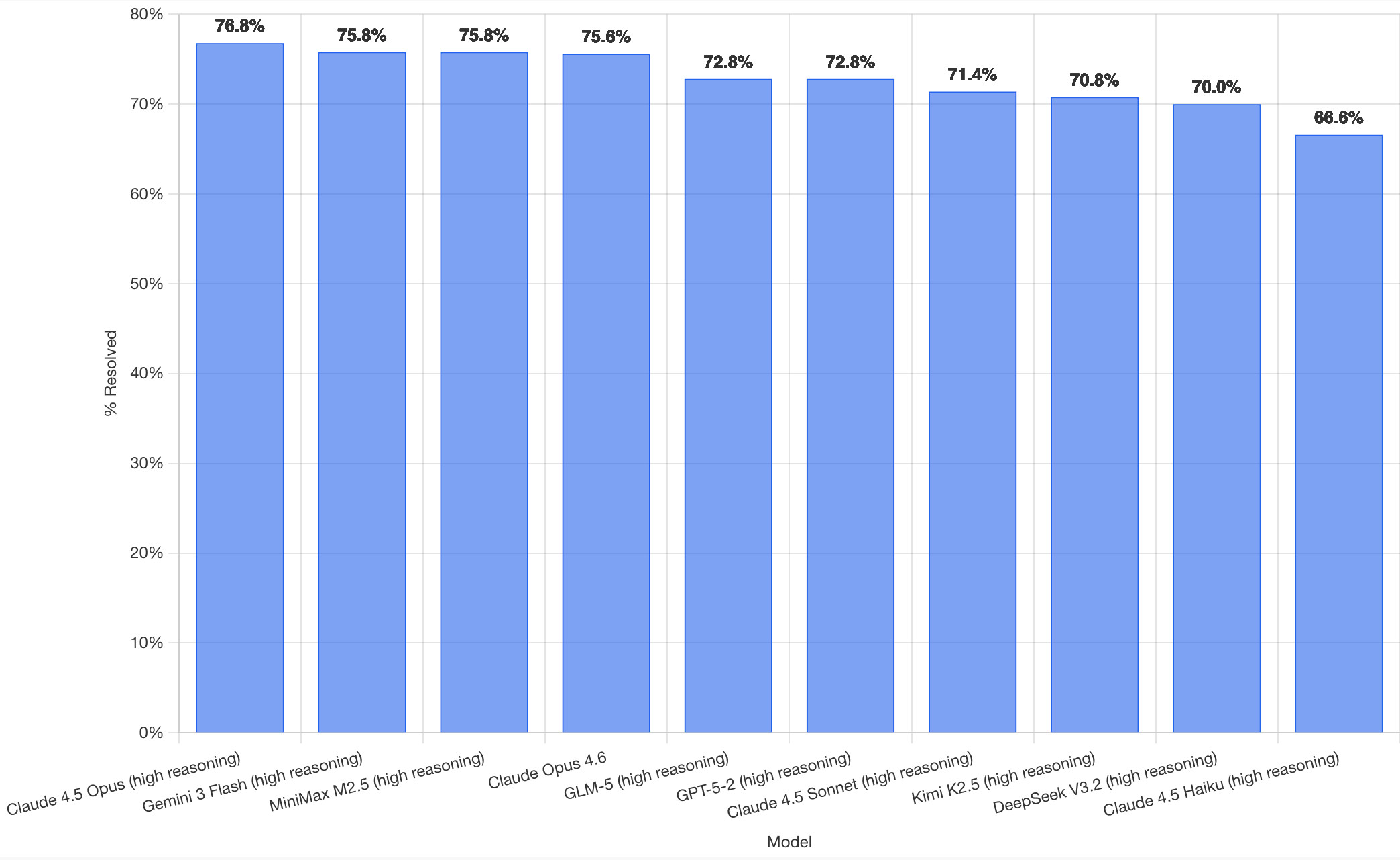 It’s interesting to see Claude Opus 4.5 beat Opus 4.6, though only by about a percentage point. 4.5 Opus is top, then Gemini 3 Flash, then MiniMax M2.5 - a 229B model released last week by Chinese lab MiniMax. GLM-5, Kimi K2.5 and DeepSeek V3.2 are three more Chinese models that make the top ten as well.
OpenAI’s GPT-5.2 is their highest performing model at position 6, but it’s worth noting that their best coding model, GPT-5.3-Codex, is not represented - maybe because it’s not yet available in the OpenAI API.
This benchmark uses the same system prompt for every model, which is important for a fair comparison but does mean that the quality of the different harnesses or optimized prompts is not being measured here.
The chart above is a screenshot from the SWE-bench website, but their charts don’t include the actual percentage values visible on the bars. I successfully used Claude for Chrome to add these - transcript here. My prompt sequence included:
It’s interesting to see Claude Opus 4.5 beat Opus 4.6, though only by about a percentage point. 4.5 Opus is top, then Gemini 3 Flash, then MiniMax M2.5 - a 229B model released last week by Chinese lab MiniMax. GLM-5, Kimi K2.5 and DeepSeek V3.2 are three more Chinese models that make the top ten as well.
OpenAI’s GPT-5.2 is their highest performing model at position 6, but it’s worth noting that their best coding model, GPT-5.3-Codex, is not represented - maybe because it’s not yet available in the OpenAI API.
This benchmark uses the same system prompt for every model, which is important for a fair comparison but does mean that the quality of the different harnesses or optimized prompts is not being measured here.
The chart above is a screenshot from the SWE-bench website, but their charts don’t include the actual percentage values visible on the bars. I successfully used Claude for Chrome to add these - transcript here. My prompt sequence included:
Use claude in chrome to open https://www.swebench.com/ Click on “Compare results” and then select “Select top 10” See those bar charts? I want them to display the percentage on each bar so I can take a better screenshot, modify the page like thatI’m impressed at how well this worked - Claude injected custom JavaScript into the page to draw additional labels on top of the existing chart.
Key Takeaways
Notable Quotes
SWE-bench is one of the benchmarks that the labs love to list in their model releases.Context: Highlighting the importance of SWE-bench in evaluating AI models.
It’s interesting to see Claude Opus 4.5 beat Opus 4.6, though only by about a percentage point.Context: Discussing the surprising performance of older AI model versions over newer ones.
I’m impressed at how well this worked - Claude injected custom JavaScript into the page to draw additional labels on top of the existing chart.Context: Expressing satisfaction with Claude’s ability to manipulate web content for enhanced visualization.
Related Topics
- [[topics/openai-api]]
- [[topics/prompt-engineering]]
- [[topics/ai-agents]]
Related Articles
[AINews] Anthropic's Agent Autonomy study
Swyx · explanation · 78% similar
Raising the bar on SWE-bench Verified with Claude 3.5 Sonnet
Anthropic Engineering · explanation · 76% similar
Eval awareness in Claude Opus 4.6’s BrowseComp performance
Anthropic Engineering · explanation · 73% similar
Originally published at https://simonwillison.net/2026/Feb/19/swe-bench/#atom-everything.